Monarchのまとめ
# 論文まとめフォーマット ## どんなもの? - Googleの内部と外部のすべてのサービスで使われる監視に用いられるインメモリデータベース - Cloud Monitoring や Managed Prometheus、課金データのためのメトリクスなど - GoogleのストレージのBigtableやストレージ基盤であるColossusの監視にも用いられる(ColossusにはBigtable(GFS版)が部分的に用いられる) ただし、Monarch自体の監視にはmetaと呼ばれる、安定した古いバージョンのMonarchが用いられる ## 先行研究と比べてどこがすごい? ### クリティカルパスでストレージ依存がない ストレージシステムの監視に用いられるため、クリティカルパスにおいてSSDやHDDに依存しない そのため、オンメモリな時系列データベースとして構築されている ### 表現力豊かなクエリ言語とデータ型 Monoachの前身である、Borgmanではヒストグラム型などがなく、99パーセンタイルなどの高度な統計分析ができなかった ### 複数ターゲットのデータ集約 オンメモリの時系列データベースであっても、スケールするようにいくつかの最適化をしている 例えば、あるDISKのIOPSデータを収集する場合ここのディスクで保存すると膨大になるため、 クラスタに含まれるDISKのIOPSにデータを集約する ### 高い可用性 ネットワークが分断されていても動作し続ける トレードオフとして、一貫性を捨てている また、一定のウィンドウサイズより遅れたデータも捨てる ## 技術や手法のキモはどこ? - 循環依存の回避 - 高度な分析ができるデータ型 - 集約により保存すべきデータの削減 - インデックスからの探索時にフィールドヒントインデックスを使うことで少ないメモリ量で高速に検索する ## どうやって有効だと判断した? ### システムスケール ### スケーラブルなクエリ #### 全体的なクエリー・パフォーマンス #### 個々のクエリのパフォーマンス ## 次に読むべき論文は? - [Slicer: Auto-sharding for datacenter applications](https://www.usenix.org/system/files/conference/osdi16/osdi16-adya.pdf) - [Time-series clustering – A decade review](https://www.sciencedirect.com/science/article/abs/pii/S0306437915000733?via%3Dihub) - [BTrDB: Optimizing Storage System Design for Timeseries Processing](https://www.usenix.org/system/files/conference/fast16/fast16-papers-andersen.pdf) - [Survey and Comparison of Open Source Time Series Databases](https://www.btw2017.informatik.uni-stuttgart.de/slidesandpapers/E4-14-109/paper_web.pdf) - [Sprintz: Time Series Compression for the Internet of Things](https://arxiv.org/abs/1808.02515)
- メモリにのみデータがあると言っているが、すべてのデータがメモリにあるわけではないはず
- どこからDISKに移行する?
この論文では対象外だった
リカバリ・ ログは圧縮され、高速読み取りに対応した形式に再書き込みされ (ログへの書 き込みは書き込みに最適化された形式のままになります) 、継続的に実行され るバックグラウンド・プロセスによって長期リポジトリにマージされます が、その詳細についてはこのドキュメントでは省略します。 また、すべての ログファイルが3つのクラスタ間で非同期にレプリケートされるため、可用性 が向上します
- 一定以上遅延したデータを破棄する場合、データの信頼性をどのように担保している?
- 欠損したデータがあることをアルゴリズム的に導くらしいがどのように?
- → あまり詳細がなかった
- 集約した場合はどのように欠損している値を表現している?
- 集約してしまった場合、欠損があるかどうかとどの程度あるかをどのように持つ?
- これは集約と欠損のトレードオフをどのようにして実現しているかと言い換えられる
- → これもあまり詳細がなかった
- どこからDISKに移行する?
データの永続化について
- Monarchではストレージシステムがとまっても動き続けるために、クリティカルパスではストレージに依存していない
- これによりストレージシステムの監視も行える
- まったくストレージを利用していないわけではなく、三箇所の異なる場所のディスクにも追記している(リカバリーログ)
- しかし、この書き込みでは書き込み完了は待たない
- 新たなノード(リーフ)の追加やノードのデータの再配置が起きた場合、リカバリーログからデータを複製しつつ、最新のデータを受け取ることで再配置を完了させる
アーキテクチャ
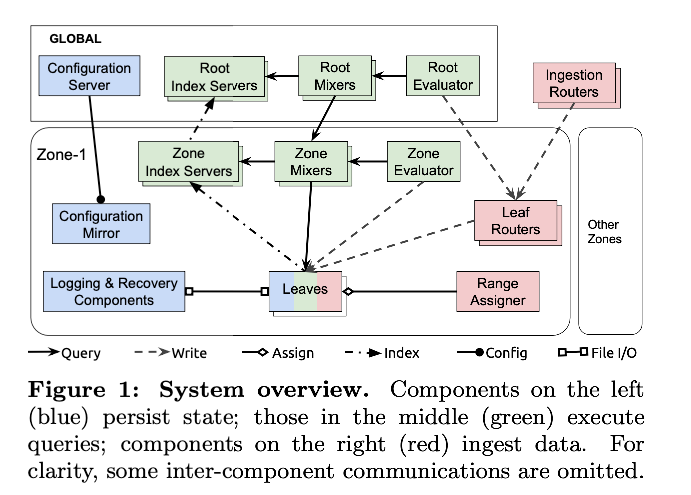
- 赤色はデータのルーティングを行うコンポーネント
- 青色が状態を保持するコンポーネント
緑色がクエリを実行するコンポーネント
Ingestion Router
- 時系列キーを基に適切なMonarchゾーンにあるリーフルーターにデータをルーティングする
- Leaf Routers
- ゾーンに保管されるデータを受け取り、保管のためにリーフに送る。
- Leaves
- 監視データをインメモリ時系列ストアに格納する。
- ルーティング・状態の保持・クエリの実行すべてをやる
- Mixers
- リーフにルーティングされて実行されるサブクエリにクエリを分割し、サブクエリの結果をマージする。 クエリは、ルートレベル (ル ートミキサー) またはゾーンレベル (ゾーンミキサー) で発行できます。 ルートレベルのクエリには、ルートミキサーとゾーンミキサーの両方 が含まれます。
- Index server
- インデックスサーバ各ゾーンおよびリーフのデータのインデックスを作成し、分散クエリの実行をガイドする
- evaluator
- 定期的に実行されるクエリを発行し、結果をリーフに書き戻す
- ダッシュボードに表示するクエリやアラート
- 定期的に実行されるクエリを発行し、結果をリーフに書き戻す
データ構造
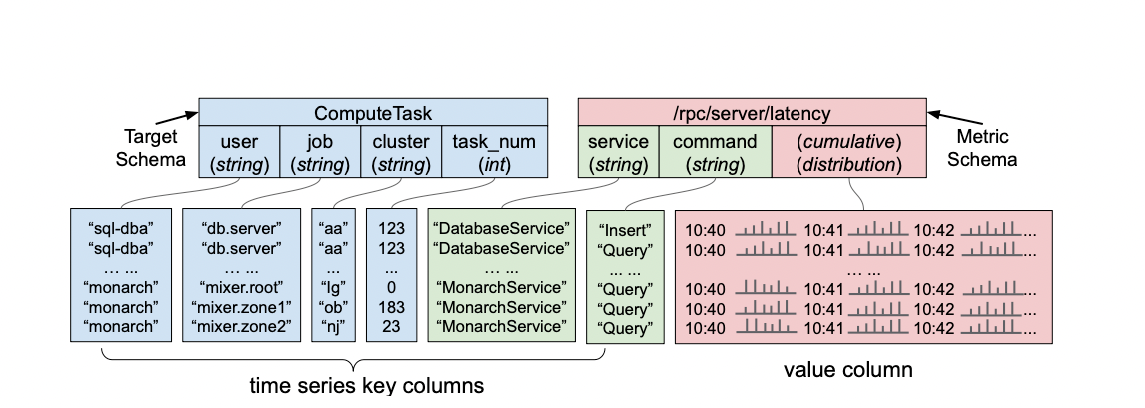
- データ構造はシンプルなKey Valueに近い形式
- Keyの前半がメトリックのターゲット
- Monarchはターゲットに含まれるデータを元に物理的に近いノードに配置する
- この例ではCluster
- Keyの後半がメトリックのデータ項目となる
- 図の例ではCompute Taskのメトリックデータであり、データの収集対象が含まれる
- Valueがタイムスタンプを伴うデータになっていて、複数のタイムスタンプにおけるデータがまとまっている
- タイムスタンプごとにKeyが分かれているわけではない
- しかし、Valueの中で同じタイムスタンプのデータはタイムシーケンスを共有する
- (ハッシュ構造みたいになってるのかな?)
青色のターゲット部分を辞書順でソートし、その値の範囲でシャーディングする
- 同じターゲットは同じLeafになるようになっている
- 特定のターゲットに関連する値や、連続した複数のターゲットを取得することが多いので、このシャーディングのおかげで単一のLeafから取得する
サポートされるデータ型としては以下
- boolean
- int 64
- double
- string
- distribution
- 「二重値のセットをバケットと呼ばれるサブセットに分割し、平均、カウント、標準偏差などの全体的な統計情報を使用して各バケットの値を要約するヒストグラムが含まれます。」
データ集約
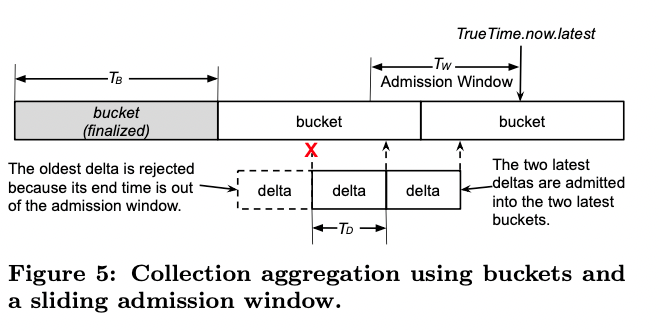
- 基本的にターゲットごとに分けて保存される
- 例えば、ディスクのI/O数(IOPS)のデータを収集する場合、個々のディスク装置がターゲットとなる
- しかし、膨大な数のディスクのデータを個別に収集するというのは、データ量の観点から現実的ではない
- 実際には、クラスターに含まれるすべてのディスクに対する総I/O数が分かれば十分ケースがある
- このような場合、複数のターゲットから送信されるデータを一定のタイムウィンドウで集約して、その合計値を保存するといった構成ができる
- 図では、「delta」と示された1つの箱がクライアントから送信されたカウント数になる
- 複数のクライアントから同様のデータが送られてきますが、これらをより長い時間間隔(TB秒間)で足し上げて、得られた結果を保存する形になる
- これが図でいう「bucket」というもの
- ここでは、「delta」に含まれるデータの末尾の時刻によって、対応する「bucket」が決まる
- 一定期間よりも古いデータは「bucket」に加えずに破棄する
- この時間の判定にはGoogle の True Time APIで判定している (Spannerでも使われている原子時計ベースのもの)
- この処理がないと、bucketの値が永遠に確定しなくなるため
- 平均的に30個程度のターゲットを集約する
- 極端なケースでは、100万を超えるターゲットのデータを1つに集約する場合もある
データの検索

Index Serverの仕組み
- Bloomフィルタと同様に偽陽性を起こすロジックを用いている
- 最終的にデータがあるかは問い合わせするため、偽陽性は実際の正確性には影響しない
- 検索対象データのキーに含まれるフィールドの値を指定すると、対応するデータを保持するLeafのリストが得られる
- この時、フィールドに含まれる値には膨大な種類がある一方、高速に処理を行うためにすべてのインデックス情報をメモリー上に保持する必要がある
- MonarchのIndex Serverでは、フィールドに含まれる値を3文字ごとに分割してインデックス化するという方法をとっている
- たとえば、"mix" という3文字の文字列に「部分文字列として"mix"を含む」という条件にマッチするLeafのリストを構成する
- フィールドに「mixer.root」という値を持つデータを保持するLeafは、このリストに含まれる
- これをアルファベットのあらゆる3文字の組み合わせについて行えば、「26×26×26」個のリストですべての組み合わせを検索できる
- 厳密には、大文字・小文字、行頭・行末記号などを含めた組み合わせを考えるので、実際のリストの数はもう少し大きくなるが、Index Serverが保持する情報は、基本的にはこの程度
- 一例として、「mixer.*」という正規表現でのフィルタリングが行われた場合を考える
- これは、「mixer」で始まる任意の文字列を意味しますので、"^m"、"mi"、"mix"、"ixe"、"xer" (「^」は文字列の先頭を表す記号)という5種類の条件すべてにマッチするLeafを選択すれば、該当データを保持するすべてのLeafを取得できる
- 「min-mixer」など、それ以外の文字列にもマッチしますが、先ほど説明したように、発見したそれぞれのLeafに対して実際に保持しているデータを問い合わせるため、正確性には問題がない
- この方法で構成したインデックス情報は、数GBのサイズに収まる
運用規模
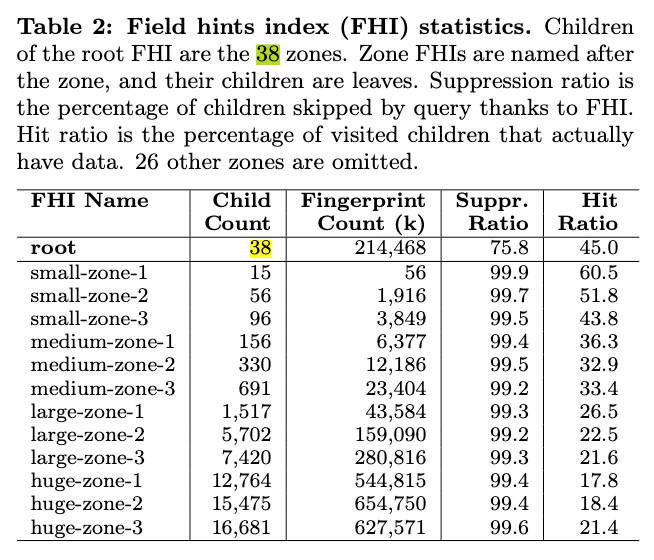
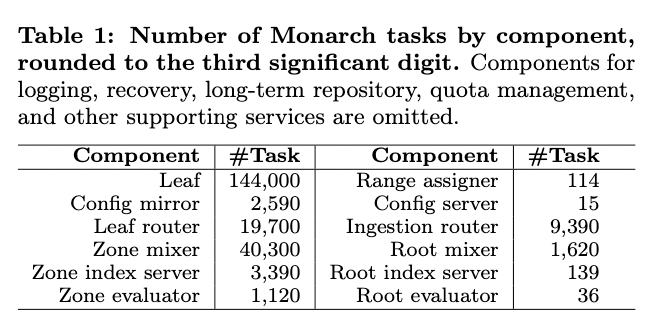
- 規模
- システム全体は38のゾーンに分散
- ゾーンは1,000〜10,000程度のLeafを持つ
- 10,000以上のLeafを持つゾーンは6カ所
- データ量
- 1秒間に約2.2TBのデータが収集される
- メモリ上に保持するデータの総量は約750TB
- 9,500億種類の時系列データ
- クエリ規模
- 1秒間に約600万回の検索処理を処理
- そのいち95%は、事前に定義された継続クエリー
- モニタリングダッシュボードに表示するためのビューの作成やアラートの生成
- 応答速度
- システム全体の中央値で79ミリ秒
- 99.9パーセンタイルでは6秒
- 数百万種類のデータを集約する複雑なクエリーでは、50秒ほどになることも